
 richardalex [_at_] meta.com
richardalex [_at_] meta.com Google Scholar
Google Scholar Twitter
Twitter











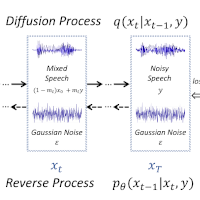
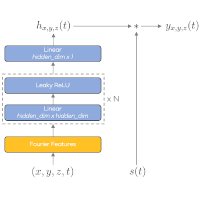

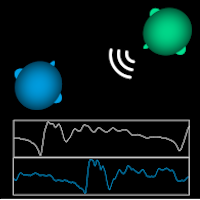
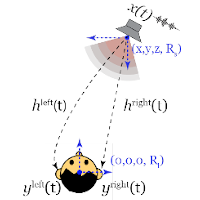






Oct 2019 - current
Research Scientist at Meta Reality Labs (formerly Facebook Reality Labs), Pittsburgh
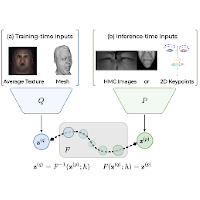
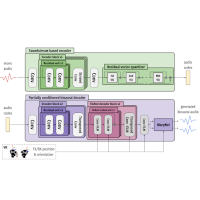
Multimodal modeling for Social VR.
Mar 2019 - Sep 2019
Scientist at Amazon Alexa, Aachen
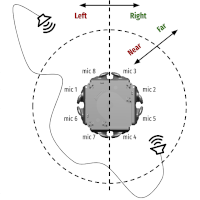
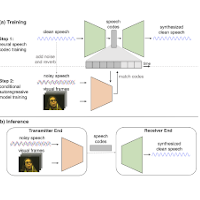
Working on Alexa at Amazon in Aachen, Germany.
Mar 2018 - Aug 2018
Research Intern at Facebook Reality Labs
Research internship at Facebook Reality Labs in Pittsburgh, working on multi-modal modeling for social VR.
Mar 2014 - Mar 2019
PhD Student, University of Bonn
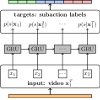
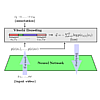
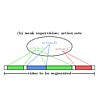
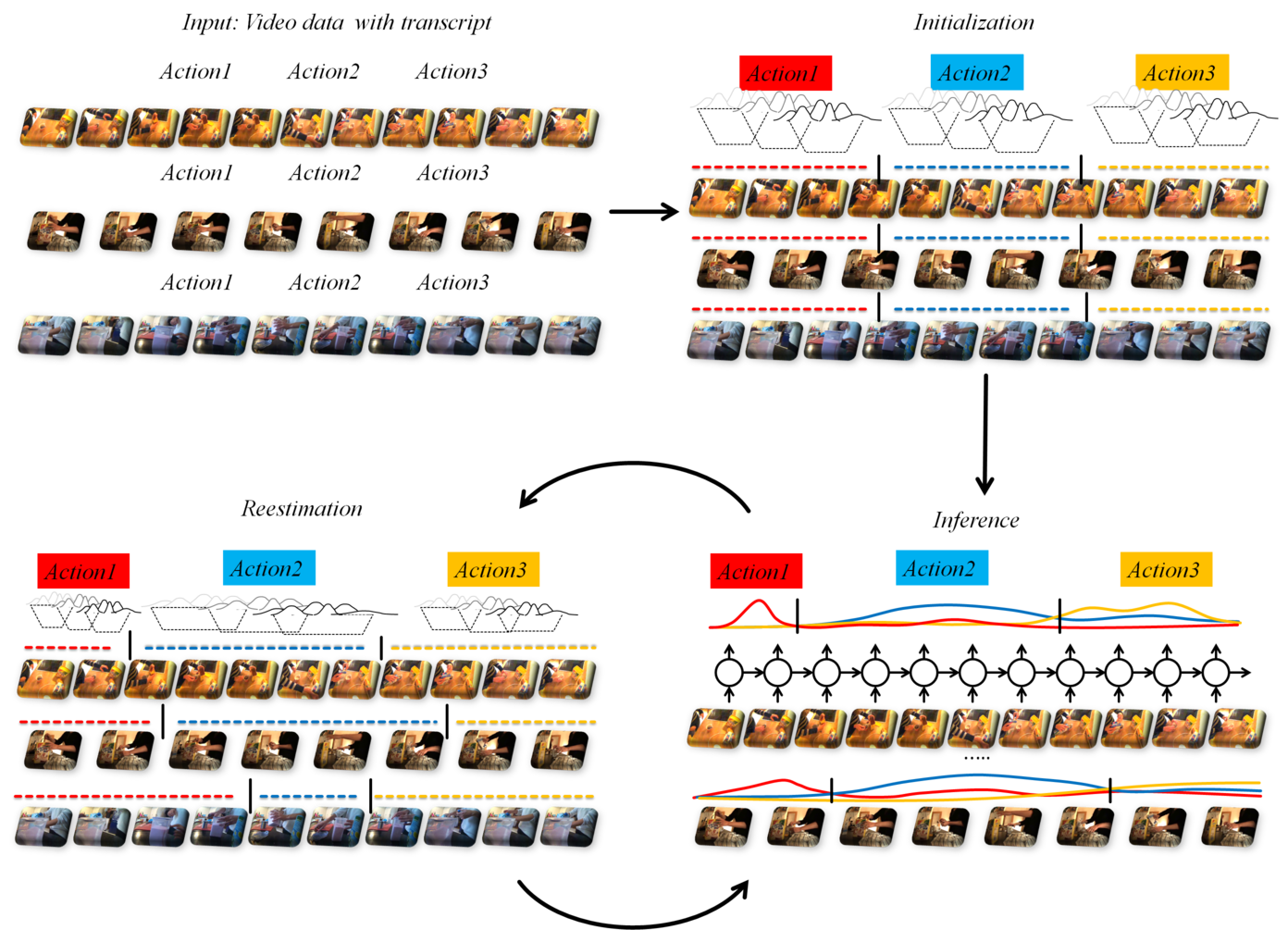
Researcher in the field of video analytics and action recognition.
Research focus on temporal action segmentation and action labeling for long, untrimmed videos containing multiple action instances.
Oct 2011 - Feb 2014
Master's Degree, RWTH Aachen University
Thesis: Improved Optimization of Neural Networks
Implementation of a neural network module for the speech recognition software RASR; design, analysis, and evaluation of a novel optimization algorihm called mean-normalized stochastic gradient descent (MN-SGD)
Oct 2008 - Sep 2011
Bachelor's Degree, RWTH Aachen University
Thesis: Optimization of Log-linear Models and Online Learning
Analytical and empirical evaluation of various optimization methods for log-linear models.